FAQs
Antworten auf häufig gestellte Fragen (FAQs)
Hier findest Du Antworten auf häufig gestellte Fragen zu unserer Software „PdfGrabber“ (Windows Version).
FAQs durchsuchen
Unter nachfolgendem Link finden Sie Standardbefehlszeilenoptionen für den Microsoft Standard Installer (Msiexec.exe), der zum Interpretieren von MSI-Paketen und installieren von Produkten unter Windows verwendet wird:
https://docs.microsoft.com/de-de/windows/win32/msi/standard-installer-command-line-options
Für mit InstallShield erzeugte Setups können gegebenenfalls die folgenden InstallShield-Paramter genutzt werden:
/v Übergibt Parameter an das MSI-Paket.
/s Stellt setup.exe so ein, dass keine Meldungen und Eingabeaufforderungen ausgegeben werden.
/l Gibt die Sprache für die Installation an.
/a Führt eine administrative Installation aus.
/j Führt die Installation im Werbungsmodus aus.
/x Führt die Deinstallation aus.
/f Startet das Installationsprogramm im Fehlerkorrekturmodus.
/w Setup.exe wartet vor dem Beenden der Verarbeitung auf den Abschluss der Installation.
/qn Ein MSI-Parameter von Windows Installer, durch den für alle Komponenten (mit Ausnahme von setup.exe) keine Meldungen und Eingabeaufforderungen mehr ausgegeben werden. Dadurch wird die Stufe für die Benutzerschnittstelle auf Null gesetzt.
Zur Installation unserer Software verwenden wir Standard-Installationsroutinen von Microsoft und InstallShield.
Sollte auf Ihrem System ein Problem bei der Deinstallation unserer Software aufgetreten sein, können Sie es eventuell mithilfe eines Tools zur Problembehandlung lösen, das im Support-Bereich von Microsoft angeboten wird:
Diese Phänomen tritt auf, wenn Sie noch eine ‚alte‘ Version von „PixelPlanet PdfPrinter“ installiert haben. Diese akzeptiert nicht die neuen PE4- bzw. PG9-Freischaldaten.
Bitte deinstallieren Sie „PixelPlanet PdfPrinter“ über ‚Systemsteuerung — Programm‘, starten Sie anschließend den Computer neu und führen Sie dann eine Neuinstallation mit der aktuellen PdfPrinter-Version durch.
PdfGrabber 8 und PdfEditor 3 sind bis einschließlich Windows 10 – Version 1607 freigegeben.
Die Folgeversion 1703 (Windows Creators-Update) ist vergleichbar mit den früher üblichen Versionssprüngen von Microsoft (z.B. „7 auf 8“ oder „8 auf 10“) und führte erhebliche Änderungen im Betriebssystem ein, die auch PdfEditor 3 und PdfGrabber 8 betreffen.
Wenn Sie PdfEditor oder PdfGrabber unter Windows 10 ab Version 1703 einsetzen möchten, aktualiseren Sie bitte auf die jeweils aktuelle Version. Entsprechende Angebote zum Update-Preis finden Sie in unserem Shop.
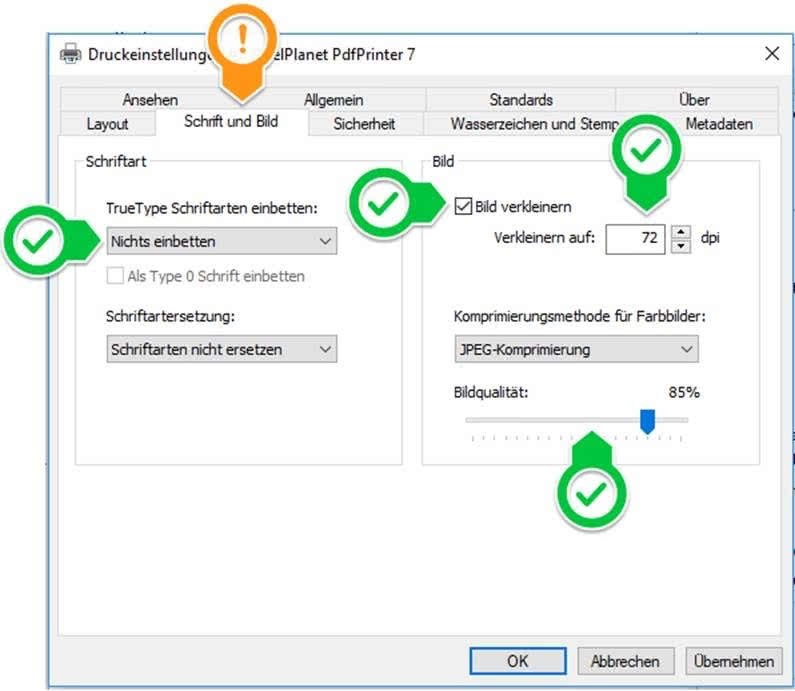
Zur Verkleinerung von PDF-Dateien kann „PixelPlanet PdfPrinter“ verwendet werden (ist in PdfEditor und PdfGrabber enthalten). Erzeugen Sie hierfür Ihr PDF einfach noch einmal neu, indem Sie es in Acrobat Reader öffnen und dann über die Druckfunktion an den „PixelPlanet PdfPrinter“ „drucken“.
In den Druckeinstellungen können folgende Optionen für die Verkleinerung der Dateigröße verwendet werden:
Die Sprachpakete der Tesseract OCR werden normalerweise unter „%programdata%\PixelPlanet\Tesseract3_5\tessdata\“ abgelegt
Sie können aber auch manuell im Programm-/Installationsverzeichnis abgelegt werden:
PdfEditor:
„%programdata%\PixelPlanet\Tesseract3_5\tessdata\“
UND
„C:\Program Files (x86)\PixelPlanet\PdfEditor 4\Tesseract3_5\tessdata\“
PdfGrabber:
„%programdata%\PixelPlanet\Tesseract3_5\tessdata\“
UND
„C:\Program Files (x86)\PixelPlanet\PdfGrabber 9\Tesseract3_5\tessdata\“
Entpacken Sie den Inhalt der gewünschten Sprachdatei (ZIP, siehe unten) in die oben genannten Verzeichnisse.
Sprachpakete:
Afrikaans,
Amharic,
Arabic,
Assamese,
Azerbaijani,
Azerbaijani – Cyrillic,
Belarusian,
Bengali,
Tibetian,
Bosnian,
Bulgarian,
Catalan,
Cebuano,
Czech,
Chinese (Simplified),
Chinese (Traditional),
Cherokee,
Welsh,
Danish,
German,
Dzongkha,
Greek (modern),
English,
English, Middle (1100-1500),
Esperanto,
Estonian,
Basque,
Persian,
Finnish,
French,
Frankish,
Hebrew,
Hindu,
Hungarian,
Indonesian,
Italian,
Japanese,
Korean,
Latvian,
Lithuanian,
Dutch,
Norwegian,
Polish,
Portuguese,
Romanian,
Russian,
Slovak,
Slovene,
Serbian,
Spanish,
Albanian,
Serbian,
Serbian (Latin),
Swedish,
Tagalog,
Thai,
Turkish,
Ukrainian,
Uzbek,
Uzbek (Cyrillic),
Vietnamese,
Yiddish
Ursachen: Die Windows-Systemregistrierung verweist eventuell fälschlicherweise auf ein temporäres Laufwerk.
Lösung:
1. Sichern Sie Ihre Windows-Registrierung.
2. Öffnen Sie das Windows-Startmenü und wählen Sie ‚Ausführen‘ (unter Windows 10: [WINDOWS + R]).
3. Geben Sie ‚regedit‘ ein und bestätigen Sie mit [ENTER]. Es öffnet sich der Windows Registrierungs-Editor.
4. Navigieren Sie zu folgendem Ordner: HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\User ShellFolders.
5. Suchen Sie in der rechten Gruppe nach Einträgen, die das falsche Laufwerk auflisten.
6. Ändern Sie falsche Angaben auf das korrekte Laufwerk.
Das Zusatzprogram „potrace“ wird für die Vektorisierung vor dem PDF-Export benötigt. Bis zur Version 8 muss es vor der ersten Anwendung von PdfGrabber nachinstalliert werden. Ab PdfGrabber 9 ist die nicht mehr erforderlich.
Auf Rechnern ohne Internetzugang oder mit eingeschränkten Rechten kann diese Installation fehlschlagen.
Laden Sie in diesem Fall „potrace“ von einem Rechner mit Internetzugang herunter.
Entpacken Sie die ZIP-Datei und speichern Sie alle darin enthaltenen Dateien in das PdfGrabber-Programmverzeichnis (z.B. „c:\Programme (x86\PixelPlanet\PdfGrabber 8.0\“).
So wird sowohl der Zugriff auf einen gegebenenfalls eingeschränkten Standardordner USER\AppData\Roaming\Potrace als auch die Downloadabfrage umgangen.
Die Schrifterkennung wird für in das Dokument eingebettete Schriften durchgeführt, bei denen das Mapping angepasst wurde (z.B. ‚X‘ liegt auf der Taste ‚A‘ etc.).
Grundvoraussetzung für die Durchführung der Schrifterkennung ist, dass im PDF-Dokument tatsächlich Schriften eingebettet sind. Weiterhin muss es sich dabei um angepasste/neu gemappte Schriften und nicht um eine Standardschrift handeln.
Diese beiden Voraussetzungen sind dann erfüllt, wenn in einem PDF-Betrachter in den Dokumenteigenschaften Einträge unter ‚Schriften‘ enthalten sind und ein Hinweis wie zum Beispiel ‚eingebettete Untergruppe‘ angegeben ist.
Damit die Schrifterkennung durchgeführt werden kann, müssen des Weiteren im PdfGrabber-Menü „Optionen – Einstellungen‘ auf dem Tab ‚Schriftoptionen‘ die folgenden Einstellungen gewählt sein:
– ‚Mitgelieferte Schriften extrahieren‘ -> Aktiviert
– ‚Extrahierte Schriften im System installieren‘ -> Aktiviert
– ‚Mitgelieferte Schriften durch Standard-Schriften ersetzen‘ -> Nicht aktiviert
PdfGrabber wurde installiert, während ein anderer Benutzer (mit Administratorrechten) angemeldet war. Sie benötigen die Anmeldedaten (Passwort) dieses oder eines anderen Benutzers mit Administratorrechten für diesen Computer.
Während der Benutzer, bei dem das Problem auftritt, angemeldet ist, werden nun folgende Schritte ausgeführt:
– Rufen Sie im Startmenü das Kontextmenü der PdfGrabber Verknüpfungüber die rechte Maustaste auf. Wählen Sie die Kontextmenü-Option ‚Ausführen als…‘. Im nächstem Fenster wählen Sie dann zunächst die Option ‚Folgender Benutzer‘ und danach in der zugehörigen Auswahlbox einen Eintrag für einen Benutzer mit Administratorrechten. Dabei ist die Eingabe des Benutzerpasswortes erforderlich.
– PdfGrabber startet:
Öffnen Sie den Menüeintrag ‚Optionen-Einstellungen‘. Auf der Registerkarte ‚Sonstiges‘ deaktivieren Sie im Bereich ‚Plugins‘ die ‚Windows-Explorer Integration‘ und die ‚Microsoft-Office Integration‘ und bestätigen dies anschließend über die Schaltfläche ‚Übernehmen‘. Anschließend aktivieren Sie die Optionen ‚Windows-Explorer Integration‘ und ‚Microsoft-Office Integration‘ wieder und schließen das Einstellungsfenster über die Schaltfläche ‚OK‘.
Sollte das Menü ‚Ausführen als…‘ nicht vorhanden sein, so kann hierfür das eingesetzte Betriebssystem ursächlich sein oder aber das Menü ist im Netz systemweit durch den Systemadministrator deaktiviert worden. In beiden Fällen kontakieren Sie bitte Ihren Systemadministrator.
Überprüfen Sie, ob es sich bei den fehlenden Objekten nicht um reine Füllflächen ohne jede Umrisslinie handelt. Dazu wiederholen Sie den Export bei aktivierter Option ‚Füllungen – Flächen füllen‘.
In dem PDF-Dokument sind sämtliche Objekte, die im PDF wie Buchstaben/Text aussehen, in Wirklichkeit Zeichenbefehle.
Beispiel: ‚i‘
Statt des im PDF-Quelltext enthaltenen Befehls ‚Textausgabe: i‘ erfolgen die Anweisungen: ‚Zeichne einen Punkt‘ sowie ‚Zeichne eine kurze senkrechte Linie‘. Wenn kein einzige Textausgabeanweisung in dem PDF-Dokument ist, wird auch keine Text-Entität in DXF erzeugt.
Zeichenanweisungen werden als Zeichenentitäten, Textausgabeanweisungen als Textentitäten exportiert. Eine Änderung der Einstellungen für die Textausgabe hat – ebenso wie die Einstellung, dass keine Texte exportiert werden sollen – keine Auswirkungen.
Bei dem Inhalt des PDF-Dokumentes handelt es sich nicht um eine Vektorgrafik, sondern um ein eingebettetes Bild und/oder die Seite wurde eingescannt. Das heisst, es stehen keine Zeichen-/Linieninformationen zur Verfügung, die eine (Rück-) Wandlung in ein DXF-Dokument ermöglichen. Sofern nur Teilbereiche fehlen, handelt es sich dabei häufig um die Legende oder das Logo der CAD-Vorlagedatei einer ansonsten mit Zeichen- und Linieninformationen verfügbaren CAD-Zeichnung. In einem Gegentest kann die Seite mit dem Profil: ‚Bilder – Enthaltene Bilder‘ exportiert werden. Sofern dabei Bilder exportiert werden, erfolgt für die entsprechenden Bereiche kein Export nach DXF.
Die Konvertierung in andere Formate ist hingegegen erfolgreich.
Viele PDF-Dokumente enthalten eingebettete Schriften. In diesen Schriften sind jedoch die Schriftzeichen anders ‚gemappt‘, d.h. die Zuordnungen sind vertauscht (das ‚ß‘ ist z.B. das ‚a‘). PdfGrabber ist mit Ausnahme von Sonderfällen in der Lage, dieses Mapping aufzulösen und den korrekten Buchstaben darzustellen. Jedoch muss dann für die Darstellung im exportieren Dokument die Originalschrift aus dem PDF-Dokument verwendet werden. Dies ist jedoch beim Export nach DXF aufgrund der Beschränkung von in DXF verwendbaren Schriften nicht möglich. Beim Export nach DXF wird je nach Einstellung versucht, auf eine Ersatzschrift zurück zu greifen. Dabei geht jedoch das aufgelöste Mapping verloren.
Formularfelder werden erst ab PdfGrabber 5 nach Word exportiert.
Wenn Sie eine ältere Version einsetzen, gehen Sie wie folgt vor: Da bei der Umwandlung in Word keine Formularelemente erzeugt werden, müssen gegebenenfalls die auszufüllenden Texte über Textfelder angelegt werden. Diese Textfelder werden einfach an die gewünschte Stelle in der exportierten Word-Datei geschoben.
Um ein Textfeld einzufügen wählen Sie in Word den Menübefehl ‚Einfügen — Textfeld‘ und ziehen dann mit der Maus an der gewünschten Stelle ein Rechteck. Nach dem eingeben des gewünschten Textes sollten Sie das Textfeld noch formatieren. Klicken Sie hierzu doppelt auf den Rand des Textfeldes und setzen Sie dann auf der Registerseite ‚Rahmen und Linien‘ unter ‚Ausfüllen‘ die ‚Farbe‘ auf ‚Keine Füllung‘. Dies wiederholen Sie unter ‚Linie‘.
In PDF-Dokumenten, die durch einen Scanner erzeugt wurden, liegt der Inhalt als große Grafik (Bild) vor. Für diese Dokumente benötigen Sie eine Texterkennung (OCR). PdfGrabber unterstützt ab Version 3 Texterkennung mittels OCR, sofern Microsoft Office 2003 auf Ihrem System installiert ist. Beachten Sie, aus gescannten Dokumenten nur die Texte extrahiert werden können. Grafiken werden nicht unterstützt.
PdfGrabber stellt in der Professional-Version für Windows die folgenden Kommandozeilenparameter zur Verfügung:
/LANGID 1031 (Deutsch)
/LANGID 1033 (Englisch)
/LANGID 1036 (Französisch)
/[„filename“] Konvertiert die angegebene Datei mit dem zuletzt ausgewählten bzw. aktuellen Profil
/profile [„profilename“] [„filename“] Für die Konvertierung wird das angegebenen Profil verwendet. Wenn kein Profilname angegeben ist, wird das zuletzt ausgewählte bzw. aktuelle Profil verwendet. Beachten Sie, dass Profilnamen nicht immer eindeutig sind, z.B. wird der Profilname „Fliesstext“ für die Exportformate Word und Text (also mehrfach) verwendet.
/profileid [„Index“] Für die Profilauswahl kann auch der Index des jeweiligen Profils verwendet werden. Der Index sollte immer dann verwendet werden, wenn der Export durch ein mitgeliefertes Standardprofil durchgeführt werden soll, dessen Profilname nicht eindeutig ist, , z.B. wird der Profilname „Fliesstext“ für die Exportformate Word und Text (also mehrfach) verwendet. Die Zuordnung von Standardprofil zu Index befindet sich am Ende dieser Anleitung.
/SILENT oder /S
Bearbeitet die angegebene Datei im Silent-Modus. PdfGrabber exportiert die Datei dabei im Hintergrund und wird abschließend wieder beendet
/close
PdfGrabber exportiert die Datei und wird abschließend wieder beendet
/show
Öffnet die konvertierten Dokumente nach erfolgreichen Export
/pages [„Seitenbereich“] Exportiert die angegebenen Seiten/Seitenbereiche, z.B. /pages „1,3-5;12“. Bei Angabe des Wertes „even“ werden alle Seiten mit geraden Seitenzahlen exportiert, bei Angabe von „odd“ alle Seiten mit ungeraden Seitenzahlen. Alle Angaben von Seitenzahlen beziehen sich dabei auf die Dokumentseiten.
/pass [„password“] Erlaubt die Angabe eines Kennwortes, sofern dies zum Öffnen bzw. Exportieren der PDF Datei notwendig ist
/output [„Verzeichnis“] Speichert die konvertierten Dateien im angegebenen Verzeichnis anstelle des vom Profil vorgegebenen Ordners.
/outfilename [„Dateiname“] Speichert die exportierte Datei unter dem angegebenen Dateinamen. Damit kann der Ausgabe-Dateiname abweichend vom Original PDF Dateinamen bestimmt werden. Speichert die exportierten Dateien bei Angabe eines kompletten Verzeichnispfades im angegebenen Verzeichnis anstelle des vom Profil vorgegebenen Ordners.
/move [„Verzeichnis“] Verschiebt die verarbeitete PDF-Datei in das angegebene Verzeichnis.
Sie können die Parameter auch mit der Demoversion testen
Beispiel:
Geben Sie folgendes in eine Windows-Eingabeaufforderung (cmd.exe) ein:
„C:\Programme (x86)\PixelPlanet\PdfGrabber 9\PdfGrabber.exe“ /profile [profilename] [filename]
Ersetzen Sie [profilename] durch den gewünschten Profilnamen (in „“ (Anführungszeichen) setzen), [filename] durch das zu konvertierende Dokument („Pfad + Name“).
Sofern in dieser Anleitung Parameterwerte in Anführungszeichen („…“) gesetzt wurden, gilt: Die Verwendung ist nicht zwingend erforderlich, wird jedoch empfohlen. Durch die generelle Verwendung wird zum Beispiel das häufig auftretende Problem vermieden, dass ein Dateipfad Leerzeichen enthält und aus diesem Grund nicht als ein zusammenhängender Parameter erkannt wird. Die Parameterbezeichner selbst mit vorangestellten ‚/‘ (also zum Beispiel der Parameter /profileid ) dürfen nicht in Anführungszeichen gesetzt werden.
Darüber hinaus bietet PdfGrabber Ansteuerungsfunktionen per COM-Interface. Die COM-Schnittstellendefinition liegt in der PdfGrabber.exe und lässt sich über einen Typbibliotheken Import in Ihre Entwicklungsumgebung integrieren.
Die Funktionen sind nicht in der Standard-Version verfügbar, der Endanwender muss also jeweils eine Professional-Version lizenzieren.
Ferner können Sie ab der Professional-Version die Funktion ‚Überwachter Ordner‘ nutzen, um den PdfGrabber durch eine Externe Anwendung anzusteuern. Hierbei kann zu jedem Profil ein Ordner definiert werden, der vom PdfGrabber überwacht wird. Sobald eine neue Datei in diesem Ordner gespeichert wird, startet der Export und die Datei wird anschließend im von Ihnen angegebenen Ausgabeverzeichnis abgelegt. Angaben zu dieser Funktion können Sie in den Optionen machen.
Eine aktuelle Liste der mitgelieferten Standardprofile nebst zugehöriger Profil-Indexe finden Sie im folgenden PDF (letzte Seite):
1. Starten Sie PdfGrabber und wählen Sie oberen Bereich des Fensters das gewünschte Ausgabeformate. PdfGrabber bietet verschiedene Ausgabeformate, die unterschiedlichen Anforderungen genügen. Für Ihr Vorhaben betätigen Sie die Schaltfläche mit dem Word-Symbol und wählen anschließend z.B. das Profil ‚Textbasiert‘.
2. Wählen Sie nun im mittleren Bereich des Fensters unter ‚Quelldokumente‘ die gewünschte PDF Datei. Um der Liste ein Dokument hinzuzufügen, wählen Sie die Schaltfläche ‚Hinzufügen‘. Im darauf folgenden Dateidialog wählen Sie die gewünschte Datei aus.
3. Wählen Sie abschließend die Schaltfläche ‚Export‘. Bevor der Exportvorgang beginnt wird Ihnen ein Zusammenfassungsfenster mit allen Einstellungen angezeigt. Hier können Sie bei Bedarf Einstellung ändern und diese als eigenes Profil speichern. Sind alle Einstellung wie gewünscht, bestätigen Sie mit ‚OK‘. Während des Exportvorgangs wird ein Meldungsfenster eingeblendet, dem Sie aktuelle Statusinformationen entnehmen können.
4. Wenn der Exportvorgang abgeschlossen ist, wird das exportierte Word-Dokument in Microsoft Word geöffnet, sofern dieses Programm auf Ihrem System installiert ist.
Wenn Sie die Dokumente mit Microsoft Word öffnen, stellen Sie sicher, dass Sie in Word unter ‚Ansicht‘ ‚Seiten-Layout‘ oder ‚Online-Layout‘ gewählt haben. Im Modus ‚Normal‘ kommt es zu dem von Ihnen geschilderten Phänomen.
Zur Lösung stehen Ihnen die folgenden Möglichkeiten zur Verfügung:
a) Versehen Sie Ihr System mit ausreichend Speicher.
b) Aktivieren Sie unter ‚Optionen — Einstellungen – Allgemein‘ die Funktion ‚Speicherverbrauch durch Auslagerungsdatei reduzieren‘.
c) Deaktivieren Sie in den Exportoptionen unter ‚Format‘ die Optionen ‚Bilder‘ und ‚Linien als Grafik ausgeben‘, um keine Grafiken auszugeben und somit die Dateigröße kleiner zu halten.
d) Exportieren Sie das Dokument schrittweise (Seite 1 – 100, Seite 101 – 200, etc.). Die gewünschten Seitenbereiche stellen Sie im Hauptfenster ein.
Stellen Sie sicher, dass Sie die aktuelle Version des PdfGrabber einsetzen. Die Ausgabe von Linien und Rahmen wird ab Version 1.0.0.24 für die RTF/Word Profile ‚Textkasten‘ und ‚Tabulator Layout‘ angeboten. Optional lassen sich Linien und Vektoren auch als Hintergrundgrafik exportieren. Aktivieren Sie hierzu in den Profiloptionen unter ‚Format — Formatoptionen‘ die Option ‚Linien als Hintergrundbild‘. Die Ausgabe von Linien, Rahmen und Vektoren mit anderen Profilen ist teilweise in Vorbereitung. Ab Version 2.5 können Rahmen und Hintergrundfarben auch beim nativen Excel-Export ausgegeben werden.
PdfGrabber (Windows-Version) wird zusammen mit ‚PixelPlanet PdfPrinter‘ ausgeliefert, mit dem die Erzeugung von PDF-Dokumenten aus jeder Anwendung über einen Druckertreiber möglich ist. Exportieren Sie also die gewünschten PDFs, führen Sie die gewünschten Änderungen durch und speichern/drucken Sie die Datei anschließend wieder als PDF.
Auf dem MAC lassen sich PDF mit Bordmitteln erstellen. Rufen Sie dazu die Druckfunktion ihrer Anwendung (z.B. Pages) auf und wählen Sie dann im Druckdialog unten links die Schaltfläche ‚PDF‘ aus.
Die Vollversion von PdfGrabber können Sie über unserer Shop oder Ihren Softwarehändler bestellen. Die Lieferung erfolgt per Download, d.h. Sie erhalten einen Freischaltschlüssel per eMail.
Wenn Sie nicht über Internet bestellen möchten, können Sie uns Ihre Bestellung auch faxen (+49 421 24778-24) oder rufen Sie uns einfach an (+49 421 24778-0).
In der Demoversion werden an zufälliger Stelle ‚X‘-Zeichen in den exportierten Text eingefügt.
Diese Einschränkung entfällt in der Vollversion von PdfGrabber.
Wenn Sie bereits eine Lizenz für PdfGrabber erworben haben und die ‚X‘-Zeichen immer noch auftauchen, stellen Sie sicher, dass Sie die Software mit den Lizenzdaten freigeschaltet haben.
Ferner werden Grafiken beim Export mit einem Stempel versehen.
Auch diese Einschränkung entfällt in der Vollversion. Die Vollversion von PdfGrabber können Sie über unserer Shop oder Ihren Softwarehändler bestellen.